Тема 1. Концепція дейтамайнінгу
1. Концепція і використання Data Mining
Дейта майніїїг (Data mining) — клас аналітичного прикладного програмного забезпечення (ППЗ), яке підтримує рішення, розшукуючи за прихованими взірцями (patterns, шаблонами, формами, зразками, образами) інформацію в базах даних. Цей пошук може бути зроблений або за допомогою користувача (виконання запитів), або інтелектуальною програмою, яка автоматично розшукує в базах даних і знаходить значущі для користувача взірці (patterns).
Data mining з англійської – добування даних; добування знань; добування інформації; аналіз, інтерпретація і представлення інформації зі сховища даних; вибирання інформації з масиву даних.
Добування даних — це процес просіювання великих обсягів даних для того, щоб виробляти відповідну контексту задачі інформацію. Термін також відомий як surfing даних (дослідження даних в Інтернеті).
Можна вирізнити п’ять загальних типів інформації, які одержуються засобами дейтамайнінгу:
- • класифікацію — робить висновок щодо визначення характеристик конкретної групи (наприклад, споживачі, які були втрачені через дії конкурентів);
- • кластеризацію (групування) — ототожнює групи елементів, які використовують спільно зображувальний параметр сигналу даних (кластеризація відрізняється від класифікації, бо наперед визначені характеристики не наводяться);
- • асоціацію — ідентифікує зв’язки або відношення між подіями, які відбувалися колись (наприклад, зміст кошика відвідання магазину за покупкою);
- • упорядковування (і послідовність) — подібне до асоціації, крім того, зв’язок ідентифікується за певні періоди часу (наприклад, повторний візит до супермаркету або фінансове планування продукту);
- • прогнозування — оцінює майбутні значення, засновані на взірцях усередині великого набору даних (наприклад, прогнозування попиту).
Інструментальні засоби добування даних використовують різноманітні техніки (методи), що дають змогу організувати пошук записів, подібних до специфічного запису чи записів; конкретизувати (або визначити) «подібність» відібраних записів; легко і швидко оглядати графічне відображення інформації в різних перспективах (ракурсах).
Головні типи інструментальних засобів, які використовуються в інтелектуальному дейтамайнінгу, такі:
- • міркування за прецедентами (case-based reasoning) — підхід з використанням історичних випадків для розпізнавання взірців;
- • нейрокомп’ютинг — підхід, за яким історичні дані досліджуються відносно розпізнавання взірців. Так, можна пройти через великі бази даних і, наприклад, ідентифікувати потенційних покупців нового продукту або компанії, профіль діяльності яких створює загрозу банкрутства даної фірми;
- • інтелектуальні агенти — один з найбільш прогресивних підходів до забирання інформації з баз даних, особливо зовнішньої. Оскільки величезні обсяги інформації стають доступними через Інтернет, виявити правильну інформацію складніше.
Текстовий майнінг (Text Mining) — розширення методів дейтамайнінгу для неструктурованих або менш структурованих текстових файлів. Він передбачає інтеграцію інструментів дейтамайнінгу (засобів аналізу числової інформації) з методами аналізу текстів природною мовою, тобто алгоритмами Text Mining. Переваги, що надаються інфраструктурою збережених даних, уможливлюють вибір додаткової корисної інформації в часовому розрізі. Наприклад, за допомогою дейтамайнінгу бази даних покупців аналітик міг би відкрити, що кожний, хто купує продукт А, також купує продукти В і С, проте пізніше, через 6 місяців.
Текстовий дейтамайнінг допомагає підприємствам:
- • знаходити «прихований» зміст документів, включаючи додаткові корисні зв’язки;
- • визначати співвідношення документів через спочатку непомічені відношення (наприклад, відкрити, що клієнти у двох різних продуктивних підрозділах мають ті самі характеристики);
- • згрупувати документи за загальними темами (наприклад, усіх клієнтів страхових фірм, хто має подібні скарги і відміняє свої страхові поліси).
Наявні на ринку систем Text Mining: Arrowsmith, ClearForest, Copemic Summarizer, DocMINER, dtSearch, DS Dataset, Enkata, Entrieva, IBM Information Mining, Intellexer, Inxight, Klarity (part of Intology tools), Kwalitan 5 for Windows, Leximancer, Lextek Profiling Engine, Megaputer Text Analyst, Recommind MindServer, SAS Text Miner, SPSS LexiQuest, Temis- Group, Text Analysis Info, Textalyser, TextPipe Pro, TextQuest, Quenza, VantagePoint, Wordstat.
Web Mining полягає в застосуванні традиційних технологій дейтамайнінгу для аналізу вкрай неоднорідної, розподіленої і значної за обсягами інформації, що міститься на web-вузлах.
У рамках Web Mining можна виділити два напрями:
- • web content mining — автоматичний пошук і витягання якісної інформації з переобтяжених «інформаційним шумом» ресурсів Інтернету, а також різноманітні засоби автоматичній класифікації і анотації документів (даний напрям споріднений з розглянутим раніше text mining);
- • web usage mining — спрямований на виявлення закономірностей у поведінці користувачів конкретного web-вузла (або групи ресурсів). Зокрема, закономірностей щодо того, які сторінки і в якій послідовності завантажуються користувачами, до яких сегментів належать ці користувачі.
Система Web Mining функціонує як експертна система збору інформації і керування контентом для web-сайту і сфокусована на трьох основних завданнях:
- • збору максимальної кількості інформації про відвідувачів сайту і завантажені ресурси;
- • дослідження зібраних даних;
- • генерації персоналізованого контенту на основі результатів досліджень (рис. 1).
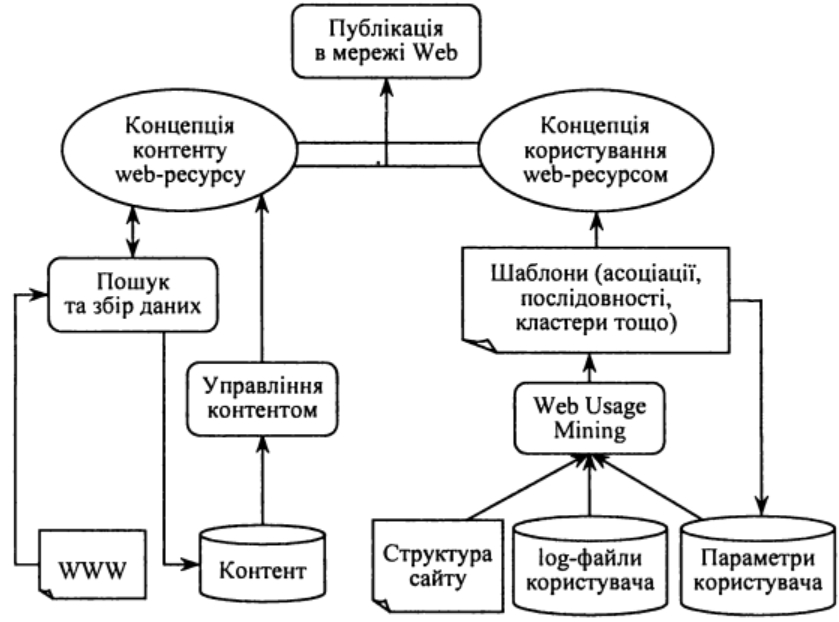
Рис. 1. Місце системи Web Mining у комплексі засобів web-персоналізації
Типова система Web Mining функціонує як HTTP ргоху- сервер, що перехоплює запити відвідувачів web-сайту. Програмна система Web Mining може також одержувати інформацію з різних зовнішніх джерел.
Маючи здатність до масштабування та модульну архітектуру, сервер Web Mining може інтелектуалізувати роботу і з електронною поштою, і з програмними агентами новин, надаючи користувачам автоматично генеровані персоналізовані інформаційні повідомлення та спрощуючи процес їх навігації.
Шрифти
Розмір шрифта
Колір тексту
Колір тла
Кернінг шрифтів
Видимість картинок
Інтервал між літерами
Висота рядка
Виділити посилання
Вирівнювання тексту
Ширина абзацу