Тема 7. Сховища даних та оперативний аналіз даних (OLAP)
3. Види OLAP-системи
В даний час на ринку присутня велика кількість продуктів, які в тій чи іншій мірі забезпечують функціональність OLAP. Забезпечуючи багатомірне концептуальне уявлення з боку користувача інтерфейсу до вихідної бази даних, всі продукти OLAP діляться на три класи за типом вихідної БД:
- MOLAP (Multidimensional OLAP) - і детальні дані, і агрегати зберігаються в багатовимірній БД. В цьому випадку виходить найбільша надмірність, так як багатовимірні дані повністю містять реляційні;
- ROLAP (Relational OLAP) - детальні дані залишаються там, де вони «жили» спочатку - в реляційній БД; агрегати зберігаються в тій же БД в спеціально створених службових таблицях;
- HOLAP (Hybrid OLAP) - детальні дані залишаються на місці (в реляційній БД), а агрегати зберігаються в багатовимірній БД.
Крім перерахованих засобів існує ще один клас - інструменти генерації запитів і звітів для настільних ПК, які доповнені функціями OLAP або інтегровані з зовнішніми засобами, що виконують такі функції. Ці добре розвинуті системи здійснюють вибірку даних з вихідних джерел, перетворюють їх і поміщають в динамічну багатовимірну БД, що функціонує на клієнтській станції кінцевого користувача.
Архітектура системи багатовимірного інтелектуального аналізу даних представлена на рис. 1.
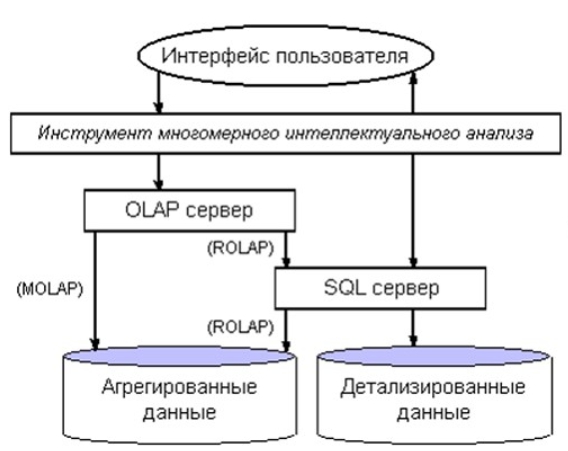
Рис. 1. Архітектура системи багатовимірного інтелектуального аналізу даних
Багатомірний OLAP (MOLAP)
Найперші системи оперативної аналітичної обробки (наприклад, Essbase компанії Arbor Software, Oracle Express Server компанії Oracle) відносились до класу MOLAP, тобто могли працювати тільки зі своїми власними багатовимірними базами даних. Вони ґрунтуються на патентованих технологіях для багатовимірних СКБД і є найбільш дорогими. Ці системи забезпечують повний цикл OLAP-обробки. Вони або включають в себе, крім серверного компонента, власний інтегрований клієнтський інтерфейс, або використовують для зв'язку з користувачем зовнішні програми, які працюють з електронними таблицями. Для обслуговування таких систем потрібен спеціальний штат співробітників, які займаються установкою, супроводженням системи, формуванням уявлень даних для кінцевих користувачів.
У спеціалізованих СКБД, заснованих на багатовимірному поданні даних, дані організовані не у формі реляційних таблиць, а у вигляді впорядкованих багатовимірних масивів:
- гіперкубів (всі збережені в БД комірки повинні мати однакову мірність, тобто знаходитися в максимально повному базисі вимірювань);
- полікубів (кожна змінна зберігається з власним набором вимірів, і всі пов'язані з цим складнощі обробки перекладаються на внутрішні механізми системи).
Використання багатовимірних БД в системах оперативної аналітичної обробки має наступні переваги:
- у разі використання багатовимірних СКБД пошук і вибірка даних здійснюється значно швидше, ніж при багатомірному концептуальному погляді на реляційну базу даних, тому що багатовимірна база даних денормалізована, містить заздалегідь агреговані показники і забезпечує оптимізований доступ до запитуваних комірок;
- багатовимірні СКБД легко справляються з завданнями включення в інформаційну модель різноманітних вбудованих функцій, тоді як об'єктивно існуючі обмеження мови SQL роблять виконання цих завдань на основі реляційних СКБД досить складним, а іноді й неможливим.
З іншого боку, є істотні обмеження:
- багатовимірні СКБД не дозволяють працювати з великими БД. До того ж за рахунок денормалізації і попередньо виконаної агрегації обсяг даних багатовимірної бази, як правило, відповідає (по оцінці Кодда) 2,5-100 разів більшому обсягу вихідних деталізованих даних;
- багатовимірні СКБД в порівнянні з реляційними дуже неефективно використовують зовнішню пам'ять. У переважній більшості випадків інформаційний гіперкуб є сильно розрідженим, а оскільки дані зберігаються в упорядкованому вигляді, невизначені значення вдається видалити тільки за рахунок вибору оптимального порядку сортування, що дозволяє організувати дані в максимально великі безперервні групи. Але навіть в цьому випадку проблема вирішується тільки частково. Крім того, оптимальний з точки зору зберігання розріджених даних порядок сортування швидше за все не буде збігатися з порядком, який найчастіше використовується у запитах. Тому в реальних системах доводиться шукати компроміс між швидкодією і надмірністю дискового простору, зайнятого базою даних.
Отже, використання багатовимірних СКБД виправдано тільки при наступних умовах.
- обсяг вихідних даних для аналізу не занадто великий (не більше декількох гігабайт), тобто рівень агрегації даних досить високий;
- набір інформаційних вимірів стабільний (оскільки будь-яка зміна в їх структурі майже завжди вимагає повної перебудови гіперкуба);
- час відповіді системи на нерегламентовані запити є найбільш критичним параметром;
- потрібно широке використання складних вбудованих функцій для виконання кросвимірних обчислень над комірками гіперкуба, в тому числі можливість написання користувацьких функцій.
Реляційний OLAP (ROLAP)
Системи оперативної аналітичної обробки реляційних даних (ROLAP) дозволяють представляти дані, що зберігаються в реляційній базі, в багатовимірній формі, забезпечуючи перетворення інформації в багатовимірну модель через проміжний шар метаданих. До цього класу належать DSS Suite компанії MicroStrategy, MetaCube компанії Informix, DecisionSuite компанії Information Advantage тощо. Подібно системам MOLAP, вони вимагають значних витрат на обслуговування фахівцями з інформаційних технологій і передбачають багатокористувацький режим роботи.
Безпосереднє використання реляційних БД в системах оперативної аналітичної обробки має наступні переваги:
- у більшості випадків корпоративні сховища даних реалізуються засобами реляційних СКБД, та інструменти ROLAP дозволяють виконувати аналіз безпосередньо над ними. При цьому розмір сховища не є таким критичним параметром, як у випадку MOLAP;
- у разі змінної розмірності задачі, коли зміни в структуру вимірювань доводиться вносити досить часто, ROLAP системи з динамічним поданням розмірності є оптимальним рішенням, так як в них такі модифікації не вимагають фізичної реорганізації БД;
- реляційні СКБД забезпечують значно вищий рівень захисту даних і хороші можливості розмежування прав доступу.
Головний недолік ROLAP в порівнянні з багатовимірними СКБД - менша продуктивність. Для забезпечення продуктивності, порівнянної з MOLAP, реляційні системи вимагають ретельного опрацювання схеми бази даних і налаштування індексів, тобто великих зусиль з боку адміністраторів БД. Тільки при використанні зіркоподібних схем продуктивність добре налаштованих реляційних систем може бути наближена до продуктивності систем на основі багатовимірних баз даних.
Ідея зіркоподібних схем полягає в тому, що є таблиці для кожного виміру, а всі факти поміщаються в одну таблицю, яка індексована множинним ключем, складеним із ключів окремих вимірів. Кожен промінь схеми зірки задає, в термінології Кодда, напрям консолідації даних за відповідним вимірюванням.
Таким чином, при великому числі незалежних вимірювань необхідно підтримувати множину таблиць фактів, відповідних кожному можливому поєднанню вибраних у запиті вимірів, що також призводить до неекономного використання зовнішньої пам'яті, збільшення часу завантаження даних в БД схеми зірки із зовнішніх джерел і складнощів адміністрування. Механізм пошуку компромісу між надмірністю та швидкодією полягає у створенні таблиць фактів не для всіх можливих поєднань вимірювань, а тільки для тих, значення комірок яких не можуть бути отримані за допомогою наступної агрегації більш повних таблиць фактів.
Таблиці фактів містять чисельні значення комірок гіперкуба, а інші таблиці визначають багатовимірний базис вимірювань, які їх містить. Частину інформації можна отримувати за допомогою динамічної агрегації даних, розподілених по не зіркоподібним нормалізованим структурам, хоча запити, що включають агрегацію, при високонормалізованій структурі БД можуть виконуватися досить повільно.
Орієнтація на уявлення багатовимірної інформації за допомогою зіркоподібних реляційних моделей дозволяє позбутися проблеми оптимізації зберігання розріджених матриць, що гостро стоїть перед багатовимірними СКБД (де проблема розрідженості вирішується спеціальним вибором схеми). Хоча для зберігання кожної комірки використовується цілий запис, який крім самих значень включає вторинні ключі - посилання на таблиці вимірювань, неіснуючі значення просто не включаються в таблицю фактів.
Гібридні OLAP (HOLAP)
Гібридні системи (Hybrid OLAP, HOLAP) розроблені з метою поєднання переваг і мінімізації недоліків, притаманних попереднім класам. До цього класу відноситься Media/MR компанії Speedware. За твердженням розробників, він об'єднує аналітичну гнучкість і швидкість відповіді MOLAP з постійним доступом до реальних даних, властивим ROLAP.
Централізація і зручне структурування - це далеко не все, що потрібно аналітику. Потрібні також інструмент для перегляду та візуалізації інформації. Традиційні звіти, навіть побудовані на основі єдиного сховища, позбавлені одного - гнучкості. Їх не можна «покрутити», «розвернути» або «згорнути», щоб отримати бажане представлення даних. Звичайно, можна викликати програміста, і він зробить новий звіт досить швидко - скажімо, протягом дня. Виходить, що аналітик може перевірити за день не більше однієї-двох ідей. А йому (якщо він хороший аналітик) таких ідей може приходити в голову по декілька на годину. І чим більше «зрізів» і «розрізів» даних аналітик бачить, тим більше у нього ідей, які, в свою чергу, для перевірки вимагають все нових і нових «зрізів». Йому потрібен такий інструмент, який дозволив би розгортати та згортати дані просто і зручно. В якості такого інструменту і виступає OLAP. Хоча OLAP і не являє собою необхідний атрибут сховища даних, він все частіше і частіше застосовується для аналізу накопичених в цьому сховищі відомостей. Компоненти, що входять в типове сховище, представлені на рис. 2.
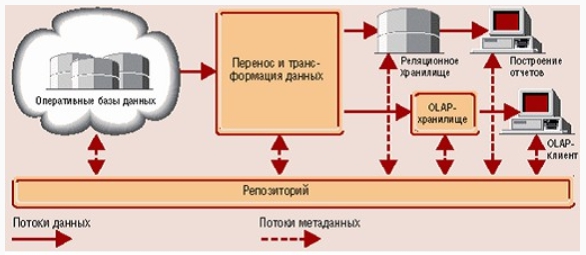
Рис. 2. Структура сховища даних
Оперативні дані збираються з різних джерел, очищаються від непотрібного, інтегруються і складаються в реляційне сховище. При цьому вони вже доступні для аналізу за допомогою різних засобів побудови звітів. Потім дані (повністю або частково) готуються для OLAP-аналізу. Вони можуть бути завантажені в спеціальну БД OLAP або залишені в реляційному сховищі. Найважливішим його елементом є метадані, тобто інформація про структуру, розміщення і трансформацію даних. Завдяки ним забезпечується ефективна взаємодія різних компонентів сховища.
Таким чином, можна визначити OLAP як сукупність засобів багатовимірного аналізу даних, накопичених у сховищі. Теоретично засоби OLAP можна застосовувати і безпосередньо до оперативних даних або їх точним копіям (щоб не заважати оперативним користувачам). Але як вже зазначалося вище оперативні дані безпосередньо для аналізу малопридатні.
Сховище даних складається з наступних компонентів:
- ПЗ проміжного шару;
- транзакційні БД і зовнішні джерела інформації;
- рівень доступу до даних;
- завантаження та попередня обробка;
- інформаційне сховище;
- метадані;
- рівень інформаційного доступу;
- рівень керування (адміністрування).
ПЗ проміжного шару
Забезпечує мережевий доступ і доступ до баз даних. Сюди відносяться мережні та комунікаційні протоколи, драйвери, системи обміну повідомленнями тощо.
Транзакційні БД і зовнішні джерела інформації
Бази даних OLTP-систем історично призначалися для ефективної обробки структур даних у відносно невеликому числі чітко визначених транзакцій. Через обмеження цільової спрямованості «облікових» систем застосовувані в них структури даних погано підходять для систем підтримки прийняття рішень. Крім того, вік багатьох встановлених OLTP-систем досягає 10 - 15 років.
Рівень доступу до даних
ПЗ, яке відноситься до цього рівня, забезпечує спілкування кінцевих користувачів з інформаційним сховищем і завантаження потрібних даних з транзакційних систем. В даний час універсальною мовою спілкування служить мова структурованих запитів (SQL).
Завантаження та попередня обробка
Цей рівень включає в себе набір засобів для завантаження даних з OLTP-систем та зовнішніх джерел. Виконується, як правило, у поєднанні з додатковою обробкою: перевіркою даних на чистоту, консолідацією, форматуванням, фільтрацією тощо.
Інформаційне сховище
Являє собою ядро всієї системи - один або декілька серверів БД.
Метадані
Метадані (репозиторій, «дані про дані»). Відіграють роль довідника, що містить відомості про джерела первинних даних, алгоритми обробки, яким вихідні дані були піддані тощо.
Рівень інформаційного доступу
Забезпечує безпосереднє спілкування користувача з даними OLAP допомогою стандартних систем маніпулювання, аналізу і надання даних типу MS Excel, MS Access, Lotus 1-2-3 тощо.
Рівень керування (адміністрування)
Відслідковує виконання процедур, необхідних для поновлення інформаційного сховища чи підтримання його стану. Тут програмуються процедури підкачки даних, перебудови індексів, виконання підсумкових (підсумовуючих) розрахунків, реплікації даних, побудови звітів, формування повідомлень користувачам, контролю цілісності тощо.
Шрифти
Розмір шрифта
Колір тексту
Колір тла
Кернінг шрифтів
Видимість картинок
Інтервал між літерами
Висота рядка
Виділити посилання
Вирівнювання тексту
Ширина абзацу