Тема 1. Концепція дейтамайнінгу
| Сайт: | Навчально-інформаційний портал НУБіП України |
| Курс: | Дейта майнінг ☑️ |
| Книга: | Тема 1. Концепція дейтамайнінгу |
| Надруковано: | Гість-користувач |
| Дата: | пʼятниця, 1 травня 2026, 23:43 |
Опис
...
1. Концепція і використання Data Mining
Дейта майніїїг (Data mining) — клас аналітичного прикладного програмного забезпечення (ППЗ), яке підтримує рішення, розшукуючи за прихованими взірцями (patterns, шаблонами, формами, зразками, образами) інформацію в базах даних. Цей пошук може бути зроблений або за допомогою користувача (виконання запитів), або інтелектуальною програмою, яка автоматично розшукує в базах даних і знаходить значущі для користувача взірці (patterns).
Data mining з англійської – добування даних; добування знань; добування інформації; аналіз, інтерпретація і представлення інформації зі сховища даних; вибирання інформації з масиву даних.
Добування даних — це процес просіювання великих обсягів даних для того, щоб виробляти відповідну контексту задачі інформацію. Термін також відомий як surfing даних (дослідження даних в Інтернеті).
Можна вирізнити п’ять загальних типів інформації, які одержуються засобами дейтамайнінгу:
- • класифікацію — робить висновок щодо визначення характеристик конкретної групи (наприклад, споживачі, які були втрачені через дії конкурентів);
- • кластеризацію (групування) — ототожнює групи елементів, які використовують спільно зображувальний параметр сигналу даних (кластеризація відрізняється від класифікації, бо наперед визначені характеристики не наводяться);
- • асоціацію — ідентифікує зв’язки або відношення між подіями, які відбувалися колись (наприклад, зміст кошика відвідання магазину за покупкою);
- • упорядковування (і послідовність) — подібне до асоціації, крім того, зв’язок ідентифікується за певні періоди часу (наприклад, повторний візит до супермаркету або фінансове планування продукту);
- • прогнозування — оцінює майбутні значення, засновані на взірцях усередині великого набору даних (наприклад, прогнозування попиту).
Інструментальні засоби добування даних використовують різноманітні техніки (методи), що дають змогу організувати пошук записів, подібних до специфічного запису чи записів; конкретизувати (або визначити) «подібність» відібраних записів; легко і швидко оглядати графічне відображення інформації в різних перспективах (ракурсах).
Головні типи інструментальних засобів, які використовуються в інтелектуальному дейтамайнінгу, такі:
- • міркування за прецедентами (case-based reasoning) — підхід з використанням історичних випадків для розпізнавання взірців;
- • нейрокомп’ютинг — підхід, за яким історичні дані досліджуються відносно розпізнавання взірців. Так, можна пройти через великі бази даних і, наприклад, ідентифікувати потенційних покупців нового продукту або компанії, профіль діяльності яких створює загрозу банкрутства даної фірми;
- • інтелектуальні агенти — один з найбільш прогресивних підходів до забирання інформації з баз даних, особливо зовнішньої. Оскільки величезні обсяги інформації стають доступними через Інтернет, виявити правильну інформацію складніше.
Текстовий майнінг (Text Mining) — розширення методів дейтамайнінгу для неструктурованих або менш структурованих текстових файлів. Він передбачає інтеграцію інструментів дейтамайнінгу (засобів аналізу числової інформації) з методами аналізу текстів природною мовою, тобто алгоритмами Text Mining. Переваги, що надаються інфраструктурою збережених даних, уможливлюють вибір додаткової корисної інформації в часовому розрізі. Наприклад, за допомогою дейтамайнінгу бази даних покупців аналітик міг би відкрити, що кожний, хто купує продукт А, також купує продукти В і С, проте пізніше, через 6 місяців.
Текстовий дейтамайнінг допомагає підприємствам:
- • знаходити «прихований» зміст документів, включаючи додаткові корисні зв’язки;
- • визначати співвідношення документів через спочатку непомічені відношення (наприклад, відкрити, що клієнти у двох різних продуктивних підрозділах мають ті самі характеристики);
- • згрупувати документи за загальними темами (наприклад, усіх клієнтів страхових фірм, хто має подібні скарги і відміняє свої страхові поліси).
Наявні на ринку систем Text Mining: Arrowsmith, ClearForest, Copemic Summarizer, DocMINER, dtSearch, DS Dataset, Enkata, Entrieva, IBM Information Mining, Intellexer, Inxight, Klarity (part of Intology tools), Kwalitan 5 for Windows, Leximancer, Lextek Profiling Engine, Megaputer Text Analyst, Recommind MindServer, SAS Text Miner, SPSS LexiQuest, Temis- Group, Text Analysis Info, Textalyser, TextPipe Pro, TextQuest, Quenza, VantagePoint, Wordstat.
Web Mining полягає в застосуванні традиційних технологій дейтамайнінгу для аналізу вкрай неоднорідної, розподіленої і значної за обсягами інформації, що міститься на web-вузлах.
У рамках Web Mining можна виділити два напрями:
- • web content mining — автоматичний пошук і витягання якісної інформації з переобтяжених «інформаційним шумом» ресурсів Інтернету, а також різноманітні засоби автоматичній класифікації і анотації документів (даний напрям споріднений з розглянутим раніше text mining);
- • web usage mining — спрямований на виявлення закономірностей у поведінці користувачів конкретного web-вузла (або групи ресурсів). Зокрема, закономірностей щодо того, які сторінки і в якій послідовності завантажуються користувачами, до яких сегментів належать ці користувачі.
Система Web Mining функціонує як експертна система збору інформації і керування контентом для web-сайту і сфокусована на трьох основних завданнях:
- • збору максимальної кількості інформації про відвідувачів сайту і завантажені ресурси;
- • дослідження зібраних даних;
- • генерації персоналізованого контенту на основі результатів досліджень (рис. 1).
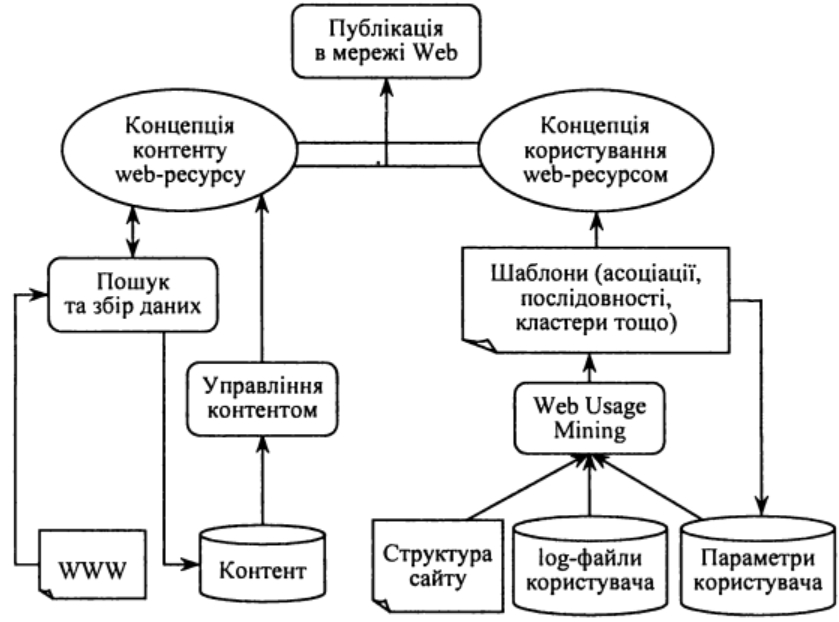
Рис. 1. Місце системи Web Mining у комплексі засобів web-персоналізації
Типова система Web Mining функціонує як HTTP ргоху- сервер, що перехоплює запити відвідувачів web-сайту. Програмна система Web Mining може також одержувати інформацію з різних зовнішніх джерел.
Маючи здатність до масштабування та модульну архітектуру, сервер Web Mining може інтелектуалізувати роботу і з електронною поштою, і з програмними агентами новин, надаючи користувачам автоматично генеровані персоналізовані інформаційні повідомлення та спрощуючи процес їх навігації.
2. Практичне застосування Data Mining
Бізнес-застосування Data Mining
Для застосування продукту Data Mining, необхідно виконати ряд кроків:
1. Встановити масштаби проекту, що визначають, які дані необхідно зібрати. Важливо, щоб проект був направлений на реалізацію реальних бізнес -цілей.
2. Розробити базу даних для Data Mining. Необхідна інформація може бути розподілена по декількох базах, іноді вона навіть зберігається не в електронній формі. Дані з різних баз необхідно консолідувати і усунути невідповідності. Насправді розвиток технології баз даних вже не вимагає застосування алгоритмів Data Mining до окремої вітрини даних. Фактично, ефективний аналіз вимагає корпоративного сховища даних, що з погляду вкладень обходиться дешевше, ніж використання окремих вітрин.
Відзначимо, що у міру впровадження Data Mining - проектів в масштабі підприємства кількість користувачів зростає, тому все частіше виникає необхідність в доступі до великомасштабних інфраструктур даних. Сучасне сховище надає не тільки ефективний спосіб зберігання всіх корпоративних даних і усуває необхідність у використанні інших вітрин і джерел, але і стає ідеальною основою для Data Mining - проектів. Репозиторій даних підприємства забезпечує узгоджені і актуальні дані про клієнтів. Упроваджуючи Data Mining функції в сховищі, компанії скорочують витрати в двох напрямах. В цьому випадку, по-перше, вже не потрібно набувати і обслуговувати додаткове устаткування для Data Mining . По-друге, компанії не потрібно переносити дані зі сховища в спеціальні джерела для Data Mining - проектів, при цьому економляться час і матеріальні ресурси.
Ще один важливий момент - очищення даних. Тут розуміється перевірка на цілісність і обробка відсутніх значень. Точність методів Data Mining залежить від якості інформації, яка лежить в їх основі. Відмітимо, що перші два етапи можуть зайняти половину (а то і більше) часу, відведеного на весь проект.
3. Застосувати алгоритми Data Mining для визначення відносин між даними. І не виключено, що для виявлення потрібних залежностей доведеться використовувати декілька різних алгоритмів. Одні з них підійдуть на перших етапах процесу, інші на пізніших. У певних випадках має сенс запустити декілька алгоритмів паралельно, щоб проаналізувати дані з різних точок зору.
4. Досліджувати співвідношення, виявлені на попередніх етапах, на застосування в масштабах проекту. На цьому етапі можливо потрібна допомога експерта в певній області. Він визначить, чи є ті або інші відносини дуже специфічними або дуже загальними і вкаже, в яких областях слід продовжити аналіз.
5. Представити результати у вигляді звіту, в якому будуть перераховані всі відносини, що інтерпретуються. Такий звіт принесе тільки одномоментну вигоду, тоді таке як застосування, що дозволяє експертові творчо підходити до виявлення відносин, набагато корисніше. Тому фірма-постачальник повинна не тільки навчити клієнта методиці пошуку залежностей в даних, але і звернути особливу увагу на навчальній роботі з самою програмою.
Також на розподіл часу для Data Mining проекту впливають і інші чинники: тип кінцевого застосування, наявність і стан сховища даних. Наприклад, якщо взяти застосування для прогнозування продажів, то виявлені відносини між даними можна використовувати до тих пір, поки не зміниться діяльність компанії. І навпаки, при аналізі споживчої корзини компанія зазвичай шукає все нові залежності в даних. Для проекту прогнозування збуту більше часу доведеться витратити на перших трьох етапах, а для аналізу споживчої корзини - на останньому.
Сфера застосування Data Mining нічим не обмежена - вона скрізь, де є які-небудь дані. Але в першу чергу методи Data Mining сьогодні, м'яко кажучи, заінтригували комерційні підприємства, що розгортають проекти на основі інформаційних сховищ даних (Data Warehousing).
Data Mining представляють велику цінність для керівників і аналітиків в їх повсякденній діяльності. Ділові люди усвідомили, що за допомогою методів Data Mining вони можуть отримати відчутні переваги в конкурентній боротьбі. Стисло охарактеризуємо деякі можливі бізнес- застосування Data Mining .
Роздрібна торгівля
Ось типові завдання, які можна вирішувати за допомогою Data Mining у сфері роздрібної торгівлі:
· аналіз купівельної корзини (аналіз схожості) призначений для виявлення товарів, яких покупці прагнуть придбати разом. Знання купівельної корзини необхідне для поліпшення реклами, вироблення стратегії створення запасів товарів і способів їх розкладки в торгових залах.
· дослідження тимчасових шаблонів допомагає торговим підприємствам приймати рішення про створення товарних запасів.
· створення прогнозуючих моделей дає можливість торговим підприємствам дізнаватися характер потреб різних категорій клієнтів з певною поведінкою. Ці знання потрібні для розробки точно направлених, економічних заходів щодо просування товарів.
Банківська справа
Досягнення технології Data Mining використовуються в банківській справі для вирішення наступних поширених завдань:
· виявлення шахрайства з кредитними картками. Шляхом аналізу минулих транзакцій, які згодом виявилися шахрайськими, банк виявляє деякі стереотипи такого шахрайства.
· сегментація клієнтів. Розбиваючи клієнтів на різні категорії, банки роблять свою маркетингову політику більш цілеспрямованою і результативною, пропонуючи різні види послуг різним групам клієнтів.
· прогнозування змін клієнтури. Data Mining допомагає банкам будувати прогнозні моделі цінності своїх клієнтів, і відповідним чином обслуговувати кожну категорію.
Телекомунікації
В області телекомунікацій методи Data Mining допомагають компаніям енергійніше просувати свої програми маркетингу і ціноутворення, щоб утримувати існуючих клієнтів і привертати нових. Серед типових заходів відзначимо наступні:
· аналіз записів про докладні характеристики викликів. Призначення такого аналізу - виявлення категорій клієнтів з схожими стереотипами користування їх послугами і розробка привабливих наборів цін і послуг;
· виявлення лояльності клієнтів. Data Mining можна використовувати для визначення характеристик клієнтів, які, один раз скориставшись послугами даної компанії, з великою часткою вірогідність залишаться їй вірними. У результаті засоби, що виділяються на маркетинг, можна витрачати там, де віддача більше всього.
Спеціальні застосування
Медицина
Відомо багато експертних систем для постановки медичних діагнозів. Вони побудовані головним чином на основі правил, що описують поєднання різних симптомів різних захворювань. За допомогою таких правил дізнаються не тільки, на що хворий пацієнт, але і як потрібно його лікувати. Правила допомагають вибирати засоби медикаментозної дії, визначати свідчення - протипоказання, орієнтуватися в лікувальних процедурах, створювати умови найбільш ефективного лікування, передбачати результати призначеного курсу лікування і т.п. Технології Data Mining дозволяють виявляти в медичних даних шаблони, складаючи основу вказаних правил.
Молекулярна генетика і генна інженерія
Мабуть, найгостріше і разом з тим чітко завдання виявлення закономірностей в експериментальних даних, стоїть в молекулярній генетиці і генній інженерії. Тут вона формулюється як визначення так званих маркерів, під якими розуміють генетичні коди, контролюючі ті або інші фенотипічні ознаки живого організму. Такі коди можуть містити сотні, тисячі і більш зв'язаних елементів.
На розвиток генетичних досліджень виділяються великі кошти. Останнім часом в даній області виник особливий інтерес до застосування методів Data Mining. Прикладна хімія
Методи Data Mining знаходять широке застосування в прикладній хімії (органічній і неорганічній). Тут нерідко виникає питання про з'ясування особливостей хімічної будови тих або інших з'єднань, що визначають їх властивості. Особливо актуальне таке завдання при аналізі складних хімічних сполук, опис яких включає сотні і тисячі структурних елементів і їх зв'язків.
3. Доступне програмне забезпечення Data Mining
На ринку програмних продуктів пропонуються десятки готових до використання систем дейтамайнінгу, причому деякі з них орієнтовані на широке охоплення технологічних засобів дейтамайнінгу, а інші грунтуються на специфічних методах (нейромережах, деревах рішень тощо). Охарактеризуємо найновіші системи ДМ з низкою різних підходів і методів дейтамайнінгу —MineSet, KnowlengeSTUDIO,PolyAnalyst. Вузькоорієнтовані на специфічні способи добування даних системи ДМ будуть згадуватися за ідентифікації найпоширеніших методів дейтамайнінгу в наступних параграфах даного розділу.
MineSet — візуальний інструмент аналітика
Компанія «Silicon Graphics» розробила систему дейтамайнінгу— MineSet, яка відрізняється специфічними особливостями як на концептуальному, так і на технологічному рівнях. Акцент при цьому робиться на унікальну процедуру візуальної інтерпретації складних взаємозв'язків у багатовимірних даних.
Система MineSet являє собою інструментарій для поглибленого інтелектуального аналізу даних на базі використання потужної візуальної парадигми. Характерною особливістю MineSet є комплексний підхід, що адаптує застосування не однієї, а кількох взаємодоповнюючих стратегій добування, аналізу й інтерпретації даних. Це дає користувачеві можливість вибирати найвідповідніший інструмент або ряд інструментів залежно від розв'язуваної задачі і видів використовуваних програмно-апаратних засобів. Архітектура MineSet має принципово відкритий характер — використовуючи стандартизований файловий формат, інші додатки можуть постачати дані для введення в MineSet, а також використовувати результати її роботи. Відкрита архітектура системи — це і основа для майбутнього її розширення, що передбачає можливість вбудовування нових компонентів на основі концепції інтеграції (plug-in). У свою чергу, інтерфейс прикладного програмування (АРІ) дає змогу інкорпорувати елементи MineSet в автономні додатки.
KnowledgeSTUDIO
Knowledge STUDIO є новою версією дейтамайнінгу корпорації з програмного забезпечення «ANGOSS» (http://www.angoss. com/). Система впроваджує найрозвинутіші методи ДМ у корпоративне середовище з тим, щоб підприємства могли досягати максимальної вигоди від своїх інвестицій у дані. Вона забезпечує високу продуктивність користувачів щодо розв'язання ділових проблем без суттєвих зусиль на навчання, як це, наприклад, потрібно для освоєння статистичного програмного забезпечення. Крім того, це також потужний інструментальний засіб для аналітиків.
KnowledgeSTUDIO сумісна з основними статистичними пакетами програм. Наприклад, ця система не тільки читає і записує файли даних, але також і генерує коди статистичного пакета SAS. Із такими властивостями стосовно статистики моделювальники можуть швидко й легко адаптувати успадковані статистичні
аналізи.
Система KnowledgeSTUDIO тісно інтегрується зі сховищами і вітринами даних. У такому разі дані можуть добуватися в режимі In-place Mining, тобто коли вони залишаються у вітрині або сховищі даних «на місці», автоматично використовуючи для цього «хвилі запитів», тобто серію тверджень SQL. Завдяки тому, що дані отримуються безпосередньо від джерела, дублювання не потребується. Альтернативно, з метою оптимізації ДМ дані можна вибирати з їх форматом зберігання, а потім дейтамайнінг виконується сервером високої продуктивності, який орієнтований на формат файлів KnowledgeSTUDIO.
Технологія ДМ ANGOSS ActiveX інтегрує моделі для прогнозування з Web-базовими додатками і бізнесовими клієнт/серверними додатками. Дослідження даних за допомогою використання дерев рішень і графіки може бути розширене через Інтранет і Інтернет, Можна також застосовувати Java-розв'язування для розгортання моделей. Для виконання алгоритмів обчислення в проекті KnowledgeSTUDIO передбачено використання або віддаленого «обчислювального» сервера, або локальної робочої станції. У KnowledgeSTUDIO реалізована велика кількість методів дейтамайнінгу. Пропонується п'ять алгоритмів дерев рішень, три алгоритми нейромереж і алгоритм кластеризації «неконтрольованого навчання» (unsupervised). Має місце повне інтегрування з додатками і бізнесовими процесами. Можна створювати нові додатки або вставляти дейтамайнінг у наявні додатки. Програмований комплекс KnowledgeSTUDIOSoftware (SDK) надає можливість розроблення додатків, наприклад створення моделей для прогнозування, з можливим використанням Visual Basic, PowerBuilder, Delphi, C++, або Java. Формування, випробування і оцінювання нових моделей може бути також автоматизованим. KnowledgeSTUDIO забезпечує різні шляхи, щоб візуально виразити і дослідити у великих базах даних зразки прихованих закономірностей.
PolyAnalyst
Компанія «Мегап'ютер» виробляє і пропонує на ринку сімейство продуктів для дейтамайнінгу — PolyAnalyst. Система PolyAnalyst призначена для автоматичного і напівавтоматичного аналізу числових баз даних і витягання з сирих даних практично корисних знань. PolyAnalyst знаходить багатофакторні залежності між змінними в базі даних, автоматично будує і тестує багатовимірні нелінійні моделі, що виражають знайдені залежності, виводить класифікаційні правила по повчальних прикладах, знаходить в даних багатовимірні кластери, будує алгоритми рішень.PolyAnalyst використовується в більш ніж 20 країнах світу для вирішення завдань з різних областей людської діяльності: бізнесу, фінансів, науки, медицини. В даний час - це одна з наймогутніших і в той же час доступних в ціновому відношенні комерційних систем для Data mining в світі. Основу PolyAnalyst складають так звані Exploration engines або Машини досліджень - математичні модулі, засновані на різних DM алгоритмах, і призначені для автоматичного аналізу даних. Компанія Megaputer Intelligence веде інтенсивні дослідження, направлені на розширення аналітичних функцій системи PolyAnalyst, розробку нових DM алгоритмів і нових математичних модулів системи.
В даний час PolyAnalyst є однією з наймогутніших систем Data Mining в світі, реалізованих для Intel платформ і операційних систем Microsoft Windows. Аналогічні системи Data Mining таких провідних виробників, як IBM (Intelligent Miner, Data Miner), Silicon Graphics (SGI Miner), Integral Solutions (Clementine), SAS Institute (SAS) працюють на середніх і великих машинах і коштують десятки і навіть сотні тисяч доларів. Завдяки унікальній технології "Еволюційного програмування", і іншим інноваційним математичним алгоритмам, PolyAnalyst поєднує в собі високу продуктивність "великих систем" з низькою вартістю, властивою програмам для Windows. PolyAnalyst - один з небагатьох комерційних продуктів, в якому реалізовані не тільки методи аналізу числових даних, але і алгоритми Text Mining, - аналізу текстової інформації. Протягом своєї більш, ніж 10-річній історії, пакет безперервно розвивається, компанія-виробник додає нову функціональність, нові математичні модулі, планується портация системи на Unix платформи. PolyAnalyst набув широкого поширення в світі. Більше 500 інсталяцій в 20 країнах світу, серед користувачів системи значний список складають найбільші світові корпорації: Boeing, 3M, Chase Manhattan Bank, Dupont, Siemens та інші. PolyAnalyst - універсальна система Data Mining, вона з успіхом застосовується в різних областях: у рішенні бізнес-задач (direct marketing, cross-selling, customer retention), в соціологічних дослідженнях, в прикладних наукових і інженерних завданнях, в банківській справі, в страхуванні і медицині.
З можливостей, SQL Server 2000 виділяють наступні:
· побудова і обробка моделей Data Mining;
· витягання даних як з реляційних, так і з багатовимірних джерел;
· два алгоритми здобування даних - Microsoft Decision Trees і Microsoft Clustering;
· розширення мови запитів до багатовимірних даних (MDX);
· робота із зовнішніми додатками через об'єктну модель DSO (Decision Support Objects).
Моделі
Моделі Data Mining - це основа витягання даних в SQL Server 2000. По суті модель є сукупність метаданих, що відображають деякі правила і закономірності в початкових даних. При цьому структура моделі визначає набір ключових атрибутів аналізу, тоді як її зміст несе безпосередньо статистичну інформацію - тут простежується схожість з ідеологією звичайних таблиць. Проте варто мати на увазі, що на основі одного і того ж набору початкових даних можна побудувати декілька різних моделей. У цьому сенсі побудова правильної моделі гарантує нам отримання саме тих “прихованих” даних, які ми прагнемо виявити.
R — мова програмування і програмне середовище для статистичних обчислень, аналізу та зображення даних в графічному вигляді. Розробка R відбувалась під істотним впливом двох наявних мов програмування: мови програмування S з семантикою успадкованою від Scheme[1]. R названа за першою літерою імен її засновників Роса Іхаки (Ross Ihaka) та Роберта Джентлмена (Robert Gentleman)[2] працівників Оклендського Університету в Новій Зеландії. Незважаючи на деякі принципові відмінності, більшість програм, написаних мовою програмування S запускаються в середовищі R.
R поширюєтся безкоштовно за ліцензією GNU General Public License у вигляді вільнодоступого вихідного коду або відкомпільованих бінарних версій більшості операційних систем: Linux, FreeBSD, Microsoft Windows, Mac OS X, Solaris. R використовує текстовий інтерфейс, однак існують різні графічні інтерфейси користувача.
R має значні можливості для здійснення статистичних аналізів, включаючи лінійну і нелінійну регресію, класичні статистичні тести, аналіз часових рядів (серій), кластерний аналіз і багато іншого. R легко розбудовується завдяки використанню додаткових функцій і пакетів доступних на сайті Comprehensive R Archive Network (CRAN). Більша частина стандартних функцій R, написана мовою R, однак існує можливість підключати код написаний C, C++, або Фортраном. Також за допомогою програмного коду на C або Java можна безпосередньо маніпулювати R об'єктами.
4. Відеоматеріали
Data Mining: How You're Revealing More Than You Think
5. Використання програми R в Data Mining
Data Mining using R | Data Mining Tutorial for Beginners
Data Mining using R | Data Mining Tutorial for Beginners
Шрифти
Розмір шрифта
Колір тексту
Колір тла
Кернінг шрифтів
Видимість картинок
Інтервал між літерами
Висота рядка
Виділити посилання
Вирівнювання тексту
Ширина абзацу