Тема 7. Сховища даних та оперативний аналіз даних (OLAP)
| Сайт: | Навчально-інформаційний портал НУБіП України |
| Курс: | Дейта майнінг ☑️ |
| Книга: | Тема 7. Сховища даних та оперативний аналіз даних (OLAP) |
| Надруковано: | Гість-користувач |
| Дата: | пʼятниця, 1 травня 2026, 20:48 |
Опис
...
1. Поняття про OLAP-системи
Кількість даних у глобальних мережах стрімко зростає практично щодня. На початку сучасної комп’ютерної ери файлові сховища задовольняли усі потреби людей щодо зберігання інформації. Потужності таких сховищ вистачало для того, аби обробляти інформацію з відносно високою швидкістю. Але уже через декілька років цей метод був неприйнятним. Створення систем керування базами даних (СКБД) свого часу стало значним проривом у галузі зберігання і обробки інформації. СКБД дали можливість оперувати величезними масивами даних, задовольняючи прийнятні часові обмеження. Навіть сьогодні СКБД залишаються основним напрямом розвитку сфери зберігання даних. В основі традиційних СКБД лежали таблиці рядкової структури. Рядкова база серіалізує всі значення одного рядка, потім значення іншого і так далі. Цей підхід вважається досить практичним, якщо мова йде про вставлення чи оновлення даних. Такі бази, оптимізовані для оновлення, називають операційними базами даних, і викорисовують у системах оперативної обробки транзакцій (OLTP). Бази, оптимізовані для читання, називають сховищами даних. Вони застосовуються у системах оперативного аналізу (OLAP) (Табл. 1).
Таблиця 1
Порівняння систем OLAP та OLTP
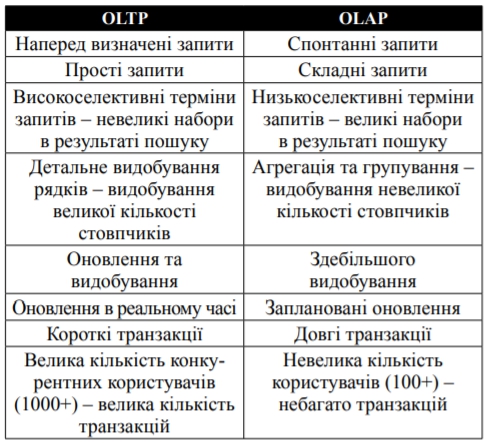
On-Line Analytical Processing (OLAP) - технологія оперативної аналітичної обробки даних, що використовує методи і засоби для збору, зберігання та аналізу багатовимірних даних з метою підтримки процесів прийняття рішень.
Бази даних онлайнової аналітичної обробки (OLAP) полегшують запити на бізнес-аналітики. OLAP – це технологія баз даних, оптимізована для запитів і звітування, а не для обробки транзакцій. Вихідні дані для OLAP – це онлайнова база даних для обробки транзакцій (OLTP), які зазвичай зберігаються в складських приміщеннях. Дані OLAP походять від цих історичних даних і агрегуються в структури, які дають можливість складного аналізу. Дані OLAP також упорядковано ієрархічно та зберігатимуться в кубах, а не в таблицях. Це складна технологія, яка використовує багатовимірні структури, щоб забезпечити швидкий доступ до даних для аналізу. Ця організація спрощує звіт зведеної таблиці або звіту зведеної діаграми, щоб відобразити зведення на високому рівні, наприклад підсумки збуту в усій країні або регіоні, а також відображати відомості про сайти, у яких збут особливо сильний або слабкий.
Бази даних OLAP призначені для прискорення отримання даних. Оскільки сервер OLAP, а не Microsoft Office Excel, обчислює підсумкові значення, менші дані потрібно надсилати до Excel, коли ви створюєте або змінюєте звіт. Цей підхід дає змогу працювати з великою кількістю вихідних даних, ніж у випадку, якщо дані було організовано в традиційній базі даних, де Excel завантажує всі окремі записи, а потім обчислює підсумкові значення.
База даних OLAP містить два основних типи даних: міри, числові дані, кількість і середні значення, які використовуються, щоб приймати обґрунтовані бізнес-рішення та розміри, які є категоріями, які використовуються для впорядкування цих заходів. Бази даних OLAP допомагають впорядкувати дані за багатьма рівнями деталізації, використовуючи ті самі категорії, які ви знайомі з аналізом даних.
OLAP куб – багатовимірне відображення даних (наприклад, продукти переглядаються за регіоном, поділом чи групою покупців). Це підхід полягає у відображенні даних у вигляді кубу, де кожна грань відповідає єдиному виміру (регіон, поділ, група).
Аналітик може зрозуміти значення, що містяться в базі даних, використовуючи багатовимірний аналіз. При зіставленні змісту даних з власною ментальною моделлю ймовірність непорозуміння чи неправильного трактування інформації значно знижується. Аналітик може переміщуватися базою, здійснювати пошук певної підмножини даних, змінюючи їх орієнтацію і виконуючи певні обчислення. Процес пошуку даних, ініційований користувачем, з використанням поворотів, проникнення вглиб і вгору часом називають «Slice and Dice».
Стандартні операції включають зріз (slice), багатошаровий зріз (dice), проникнення вглиб (drill down), згортку (roll up), а також вісь повороту (pivot) [3]:
● зріз: це підмножина багатовимірного масиву, що відповідає одному значенню для одного чи кількох членів вимірів, які не потрапили до підмножини;
● багатовимірний зріз: операція багатовимірного зрізу – це зріз по більше, ніж двох вимірах кубу даних;
● проникнення вглиб/вгору: ця операція є спеціальним аналітичним методом, за якого користувач проглядає різні рівні даних, починаючи з найбільш загального і закінчуючи найбільш деталізованим (згори донизу), або навпаки;
● згортка: при згортці обчислюються всі відношення між даними для одного або декількох вимірів. Для цього може бути наперед визначена формула;
● вісь повороту: використовується для зміни орієнтації виміру.
2. Вимоги до OLAP-системи
Властивості інформаційних сховищ
Розробники виділяють наступні властивості:
- предметна орієнтація;
- інтегрованість даних;
- інваріантність у часі;
- непорушність - стабільність інформації;
- мінімізація надмірності інформації.
Предметна орієнтація
На відміну від БД в традиційних OLTP-системах, де дані підібрані у відповідності з конкретними додатками, інформація в OLAP орієнтована на задачі підтримки прийняття рішень. Для системи підтримки прийняття рішень потрібні «історичні» дані - факти продажів за певні проміжки часу. Добре спроектовані структури даних OLAP відображають розвиток всіх напрямків бізнесу компанії в часі.
Оскільки в OLAP-технології об'єкти даних виходять на перший план, то особливі вимоги пред'являються до структур БД, які використовуються для створення інформаційних сховищ. Принципово відрізняються і структури баз даних для OLTP-й OLAP-систем. У другому випадку в них міститься тільки та інформація, яка може бути корисною для роботи систем підтримки прийняття рішень (DSS).
Інтегрованість даних
Дані в інформаційне сховище надходять з різних джерел, де вони можуть мати різні імена, атрибути, одиниці виміру і способи кодування. Після завантаження в OLAP дані очищаються від індивідуальних ознак, тобто як би приводяться до спільного знаменника. З цього моменту вони представляються користувачу у вигляді єдиного інформаційного простору.
Наприклад, якщо в чотирьох різних додатках стать клієнта кодувалася чотирма різними способами, то в інформаційному сховищі буде використана єдина для всіх даних схема кодування (ч або ж).
Інваріантність у часі
У OLTP-системах істинність даних гарантована тільки в момент читання, оскільки вже в наступну мить вони можуть змінитися в результаті чергової транзакції. Важливою відмінністю OLAP від OLTP-систем є те, що дані в них зберігають свою істинність в будь-який момент процесу читання.
У OLTP-системах інформація часто модифікується як результат виконання яких-небудь транзакцій. Тимчасова інваріантність даних в OLAP досягається за рахунок введення полів з атрибутом «час» (день, тиждень, місяць) в ключі таблиць. В результаті записи в таблицях OLAP ніколи не змінюються, являючи собою знімки даних, зроблені в певні відрізки часу. В OLAP містяться як би моментальні знімки даних. Кожен елемент у своєму ключі явно або опосередковано зберігає часовий параметр, наприклад день, місяць або рік.
Непорушність - стабільність інформації
У OLTP-системах записи можуть регулярно додаватися, вилучатися і редагуватися. В OLAP-системах, як випливає з вимоги тимчасової інваріантності, одного разу завантажені дані теоретично ніколи не змінюються. По відношенню до них можливі тільки дві операції: початкове завантаження і читання (доступ). Це і визначає специфіку проектування структури бази даних для OLAP. Якщо при створенні OLTP-систем розробники повинні враховувати такі моменти, як відкати транзакцій після збою сервера, боротьба з взаємними блокуваннями процесів (deadlocks), збереження цілісності даних, то для OLAP дані проблеми не настільки актуальні - перед розробниками стоять інші завдання, пов'язані, наприклад, із забезпеченням високої швидкості доступу до даних.
Мінімізація надмірності інформації
Оскільки інформація в OLAP завантажується з OLTP-систем, виникає питання, чи не веде це до надмірної надмірності даних? Насправді надмірність мінімальна (близько 1%!), Що пояснюється наступними причинами:
- при завантаженні інформації з OLTP-cистем в OLAP дані фільтруються. Багато з них взагалі не потрапляють в OLAP, оскільки позбавлені сенсу з точки зору використання в системах підтримки прийняття рішень;
- інформація в OLTP-системах носить, як правило, оперативний характер, і дані, втративши актуальність, видаляються. В OLAP, навпаки, зберігається історична інформація, і з цієї точки зору перекриття вмісту OLAP даними OLTP-систем виявляється досить незначним;
- в OLAP зберігається якась підсумкова інформація, яка в базах даних OLTP-систем взагалі відсутня;
- під час завантаження в OLAP записи сортуються, очищаються від непотрібної інформації та призводять до єдиного формату. Після такої обробки це вже зовсім інші дані.
3. Види OLAP-системи
В даний час на ринку присутня велика кількість продуктів, які в тій чи іншій мірі забезпечують функціональність OLAP. Забезпечуючи багатомірне концептуальне уявлення з боку користувача інтерфейсу до вихідної бази даних, всі продукти OLAP діляться на три класи за типом вихідної БД:
- MOLAP (Multidimensional OLAP) - і детальні дані, і агрегати зберігаються в багатовимірній БД. В цьому випадку виходить найбільша надмірність, так як багатовимірні дані повністю містять реляційні;
- ROLAP (Relational OLAP) - детальні дані залишаються там, де вони «жили» спочатку - в реляційній БД; агрегати зберігаються в тій же БД в спеціально створених службових таблицях;
- HOLAP (Hybrid OLAP) - детальні дані залишаються на місці (в реляційній БД), а агрегати зберігаються в багатовимірній БД.
Крім перерахованих засобів існує ще один клас - інструменти генерації запитів і звітів для настільних ПК, які доповнені функціями OLAP або інтегровані з зовнішніми засобами, що виконують такі функції. Ці добре розвинуті системи здійснюють вибірку даних з вихідних джерел, перетворюють їх і поміщають в динамічну багатовимірну БД, що функціонує на клієнтській станції кінцевого користувача.
Архітектура системи багатовимірного інтелектуального аналізу даних представлена на рис. 1.
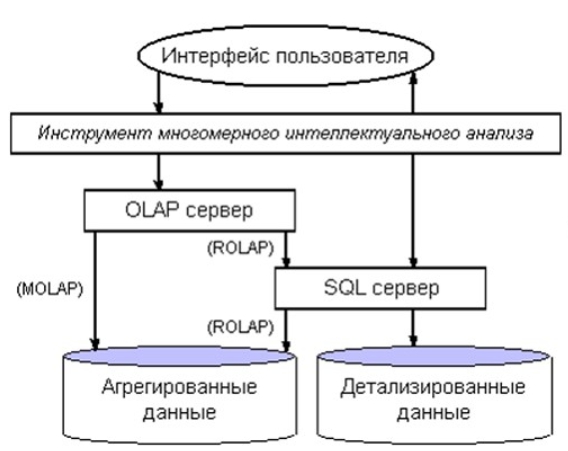
Рис. 1. Архітектура системи багатовимірного інтелектуального аналізу даних
Багатомірний OLAP (MOLAP)
Найперші системи оперативної аналітичної обробки (наприклад, Essbase компанії Arbor Software, Oracle Express Server компанії Oracle) відносились до класу MOLAP, тобто могли працювати тільки зі своїми власними багатовимірними базами даних. Вони ґрунтуються на патентованих технологіях для багатовимірних СКБД і є найбільш дорогими. Ці системи забезпечують повний цикл OLAP-обробки. Вони або включають в себе, крім серверного компонента, власний інтегрований клієнтський інтерфейс, або використовують для зв'язку з користувачем зовнішні програми, які працюють з електронними таблицями. Для обслуговування таких систем потрібен спеціальний штат співробітників, які займаються установкою, супроводженням системи, формуванням уявлень даних для кінцевих користувачів.
У спеціалізованих СКБД, заснованих на багатовимірному поданні даних, дані організовані не у формі реляційних таблиць, а у вигляді впорядкованих багатовимірних масивів:
- гіперкубів (всі збережені в БД комірки повинні мати однакову мірність, тобто знаходитися в максимально повному базисі вимірювань);
- полікубів (кожна змінна зберігається з власним набором вимірів, і всі пов'язані з цим складнощі обробки перекладаються на внутрішні механізми системи).
Використання багатовимірних БД в системах оперативної аналітичної обробки має наступні переваги:
- у разі використання багатовимірних СКБД пошук і вибірка даних здійснюється значно швидше, ніж при багатомірному концептуальному погляді на реляційну базу даних, тому що багатовимірна база даних денормалізована, містить заздалегідь агреговані показники і забезпечує оптимізований доступ до запитуваних комірок;
- багатовимірні СКБД легко справляються з завданнями включення в інформаційну модель різноманітних вбудованих функцій, тоді як об'єктивно існуючі обмеження мови SQL роблять виконання цих завдань на основі реляційних СКБД досить складним, а іноді й неможливим.
З іншого боку, є істотні обмеження:
- багатовимірні СКБД не дозволяють працювати з великими БД. До того ж за рахунок денормалізації і попередньо виконаної агрегації обсяг даних багатовимірної бази, як правило, відповідає (по оцінці Кодда) 2,5-100 разів більшому обсягу вихідних деталізованих даних;
- багатовимірні СКБД в порівнянні з реляційними дуже неефективно використовують зовнішню пам'ять. У переважній більшості випадків інформаційний гіперкуб є сильно розрідженим, а оскільки дані зберігаються в упорядкованому вигляді, невизначені значення вдається видалити тільки за рахунок вибору оптимального порядку сортування, що дозволяє організувати дані в максимально великі безперервні групи. Але навіть в цьому випадку проблема вирішується тільки частково. Крім того, оптимальний з точки зору зберігання розріджених даних порядок сортування швидше за все не буде збігатися з порядком, який найчастіше використовується у запитах. Тому в реальних системах доводиться шукати компроміс між швидкодією і надмірністю дискового простору, зайнятого базою даних.
Отже, використання багатовимірних СКБД виправдано тільки при наступних умовах.
- обсяг вихідних даних для аналізу не занадто великий (не більше декількох гігабайт), тобто рівень агрегації даних досить високий;
- набір інформаційних вимірів стабільний (оскільки будь-яка зміна в їх структурі майже завжди вимагає повної перебудови гіперкуба);
- час відповіді системи на нерегламентовані запити є найбільш критичним параметром;
- потрібно широке використання складних вбудованих функцій для виконання кросвимірних обчислень над комірками гіперкуба, в тому числі можливість написання користувацьких функцій.
Реляційний OLAP (ROLAP)
Системи оперативної аналітичної обробки реляційних даних (ROLAP) дозволяють представляти дані, що зберігаються в реляційній базі, в багатовимірній формі, забезпечуючи перетворення інформації в багатовимірну модель через проміжний шар метаданих. До цього класу належать DSS Suite компанії MicroStrategy, MetaCube компанії Informix, DecisionSuite компанії Information Advantage тощо. Подібно системам MOLAP, вони вимагають значних витрат на обслуговування фахівцями з інформаційних технологій і передбачають багатокористувацький режим роботи.
Безпосереднє використання реляційних БД в системах оперативної аналітичної обробки має наступні переваги:
- у більшості випадків корпоративні сховища даних реалізуються засобами реляційних СКБД, та інструменти ROLAP дозволяють виконувати аналіз безпосередньо над ними. При цьому розмір сховища не є таким критичним параметром, як у випадку MOLAP;
- у разі змінної розмірності задачі, коли зміни в структуру вимірювань доводиться вносити досить часто, ROLAP системи з динамічним поданням розмірності є оптимальним рішенням, так як в них такі модифікації не вимагають фізичної реорганізації БД;
- реляційні СКБД забезпечують значно вищий рівень захисту даних і хороші можливості розмежування прав доступу.
Головний недолік ROLAP в порівнянні з багатовимірними СКБД - менша продуктивність. Для забезпечення продуктивності, порівнянної з MOLAP, реляційні системи вимагають ретельного опрацювання схеми бази даних і налаштування індексів, тобто великих зусиль з боку адміністраторів БД. Тільки при використанні зіркоподібних схем продуктивність добре налаштованих реляційних систем може бути наближена до продуктивності систем на основі багатовимірних баз даних.
Ідея зіркоподібних схем полягає в тому, що є таблиці для кожного виміру, а всі факти поміщаються в одну таблицю, яка індексована множинним ключем, складеним із ключів окремих вимірів. Кожен промінь схеми зірки задає, в термінології Кодда, напрям консолідації даних за відповідним вимірюванням.
Таким чином, при великому числі незалежних вимірювань необхідно підтримувати множину таблиць фактів, відповідних кожному можливому поєднанню вибраних у запиті вимірів, що також призводить до неекономного використання зовнішньої пам'яті, збільшення часу завантаження даних в БД схеми зірки із зовнішніх джерел і складнощів адміністрування. Механізм пошуку компромісу між надмірністю та швидкодією полягає у створенні таблиць фактів не для всіх можливих поєднань вимірювань, а тільки для тих, значення комірок яких не можуть бути отримані за допомогою наступної агрегації більш повних таблиць фактів.
Таблиці фактів містять чисельні значення комірок гіперкуба, а інші таблиці визначають багатовимірний базис вимірювань, які їх містить. Частину інформації можна отримувати за допомогою динамічної агрегації даних, розподілених по не зіркоподібним нормалізованим структурам, хоча запити, що включають агрегацію, при високонормалізованій структурі БД можуть виконуватися досить повільно.
Орієнтація на уявлення багатовимірної інформації за допомогою зіркоподібних реляційних моделей дозволяє позбутися проблеми оптимізації зберігання розріджених матриць, що гостро стоїть перед багатовимірними СКБД (де проблема розрідженості вирішується спеціальним вибором схеми). Хоча для зберігання кожної комірки використовується цілий запис, який крім самих значень включає вторинні ключі - посилання на таблиці вимірювань, неіснуючі значення просто не включаються в таблицю фактів.
Гібридні OLAP (HOLAP)
Гібридні системи (Hybrid OLAP, HOLAP) розроблені з метою поєднання переваг і мінімізації недоліків, притаманних попереднім класам. До цього класу відноситься Media/MR компанії Speedware. За твердженням розробників, він об'єднує аналітичну гнучкість і швидкість відповіді MOLAP з постійним доступом до реальних даних, властивим ROLAP.
Централізація і зручне структурування - це далеко не все, що потрібно аналітику. Потрібні також інструмент для перегляду та візуалізації інформації. Традиційні звіти, навіть побудовані на основі єдиного сховища, позбавлені одного - гнучкості. Їх не можна «покрутити», «розвернути» або «згорнути», щоб отримати бажане представлення даних. Звичайно, можна викликати програміста, і він зробить новий звіт досить швидко - скажімо, протягом дня. Виходить, що аналітик може перевірити за день не більше однієї-двох ідей. А йому (якщо він хороший аналітик) таких ідей може приходити в голову по декілька на годину. І чим більше «зрізів» і «розрізів» даних аналітик бачить, тим більше у нього ідей, які, в свою чергу, для перевірки вимагають все нових і нових «зрізів». Йому потрібен такий інструмент, який дозволив би розгортати та згортати дані просто і зручно. В якості такого інструменту і виступає OLAP. Хоча OLAP і не являє собою необхідний атрибут сховища даних, він все частіше і частіше застосовується для аналізу накопичених в цьому сховищі відомостей. Компоненти, що входять в типове сховище, представлені на рис. 2.
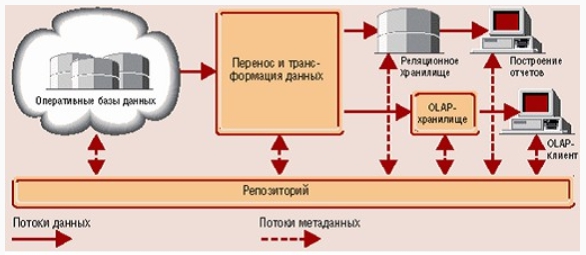
Рис. 2. Структура сховища даних
Оперативні дані збираються з різних джерел, очищаються від непотрібного, інтегруються і складаються в реляційне сховище. При цьому вони вже доступні для аналізу за допомогою різних засобів побудови звітів. Потім дані (повністю або частково) готуються для OLAP-аналізу. Вони можуть бути завантажені в спеціальну БД OLAP або залишені в реляційному сховищі. Найважливішим його елементом є метадані, тобто інформація про структуру, розміщення і трансформацію даних. Завдяки ним забезпечується ефективна взаємодія різних компонентів сховища.
Таким чином, можна визначити OLAP як сукупність засобів багатовимірного аналізу даних, накопичених у сховищі. Теоретично засоби OLAP можна застосовувати і безпосередньо до оперативних даних або їх точним копіям (щоб не заважати оперативним користувачам). Але як вже зазначалося вище оперативні дані безпосередньо для аналізу малопридатні.
Сховище даних складається з наступних компонентів:
- ПЗ проміжного шару;
- транзакційні БД і зовнішні джерела інформації;
- рівень доступу до даних;
- завантаження та попередня обробка;
- інформаційне сховище;
- метадані;
- рівень інформаційного доступу;
- рівень керування (адміністрування).
ПЗ проміжного шару
Забезпечує мережевий доступ і доступ до баз даних. Сюди відносяться мережні та комунікаційні протоколи, драйвери, системи обміну повідомленнями тощо.
Транзакційні БД і зовнішні джерела інформації
Бази даних OLTP-систем історично призначалися для ефективної обробки структур даних у відносно невеликому числі чітко визначених транзакцій. Через обмеження цільової спрямованості «облікових» систем застосовувані в них структури даних погано підходять для систем підтримки прийняття рішень. Крім того, вік багатьох встановлених OLTP-систем досягає 10 - 15 років.
Рівень доступу до даних
ПЗ, яке відноситься до цього рівня, забезпечує спілкування кінцевих користувачів з інформаційним сховищем і завантаження потрібних даних з транзакційних систем. В даний час універсальною мовою спілкування служить мова структурованих запитів (SQL).
Завантаження та попередня обробка
Цей рівень включає в себе набір засобів для завантаження даних з OLTP-систем та зовнішніх джерел. Виконується, як правило, у поєднанні з додатковою обробкою: перевіркою даних на чистоту, консолідацією, форматуванням, фільтрацією тощо.
Інформаційне сховище
Являє собою ядро всієї системи - один або декілька серверів БД.
Метадані
Метадані (репозиторій, «дані про дані»). Відіграють роль довідника, що містить відомості про джерела первинних даних, алгоритми обробки, яким вихідні дані були піддані тощо.
Рівень інформаційного доступу
Забезпечує безпосереднє спілкування користувача з даними OLAP допомогою стандартних систем маніпулювання, аналізу і надання даних типу MS Excel, MS Access, Lotus 1-2-3 тощо.
Рівень керування (адміністрування)
Відслідковує виконання процедур, необхідних для поновлення інформаційного сховища чи підтримання його стану. Тут програмуються процедури підкачки даних, перебудови індексів, виконання підсумкових (підсумовуючих) розрахунків, реплікації даних, побудови звітів, формування повідомлень користувачам, контролю цілісності тощо.
4. Переваги OLAP-системи
Через використання аналітичних сервісів досягається автоматизація звітності шляхом можливостей:
- Виконувати аналітичні задачі високої складності.
- Виконувати прогнозування на основі багатовимірної інформації.
- Розробляти безліч варіантів планів.
- Використовувати будь-яку інформацію незалежно від обсягу, місця зберігання.
- Отримувати доступ кількох користувачів із забезпеченням необхідної безпеки:блокування, авторизації.
- Багатовимірного концептуального виведення інформації.
При цьому обов’язковою умовою є подання даних з підтримкою ієрархії. Швидко отримувати результати. OLAP аналіз і отримання даних зазвичай не перевищує 5 секунд. За допомогою системи можна аналізувати дані як в найпростіших офісних додатках (Excel), так і в найпотужніших програмах, що базуються на серверних продуктах (Tableau, QlickView, MS Power BI). Переваги OLAP систем Можливість відстеження причинно-наслідкових зв’язків. Можливість отримання різноманітних прогнозів. Легка і проста настройка деталізації звітів: кожен користувач може створювати звіт виключно з необхідною інформацією. Багатовимірні зв’язки дозволяють виявити приховані залежності. Створення будь-яких прогнозів і управління будь-якими процесами: прогноз бюджету, KPI торгових представників (KPI – ключові показники ефективності), прогноз закупівель, аналітичні звіти з продажу, визначення плану стратегічного розвитку і т.д.
Архітектура OLAP-додатків
Все, що говорилося вище про OLAP, по суті, відносилося до багатомірного представлення даних. Те, як дані зберігаються не цікавить ні кінцевого користувача, ні розробників інструменту, яким клієнт користується.
Багатомірність в OLAP-додатках може бути розділена на три рівні:
- багатовимірне представлення даних - засоби кінцевого користувача, що забезпечують багатомірну візуалізацію та маніпулювання даними; шар багатовимірного представлення абстраговані від фізичної структури даних і сприймає дані як багатовимірні;
- багатовимірна обробка - засіб (мова) формулювання багатовимірних запитів (традиційну реляційну мову SQL тут виявляють непридатною) і процесор, що уміє обробити і виконати такий запит;
- багатовимірне зберігання - засоби фізичної організації даних, що забезпечують ефективне виконання багатовимірних запитів.
Перші два рівня в обов'язковому порядку присутні у всіх OLAP-засобах. Третій рівень, хоча і є широко поширеним, не обов'язковий, так як дані для багатовимірного представлення можуть вилучатись і зі звичайних реляційних структур; процесор багатовимірних запитів у цьому випадку транслює багатовимірні запити в SQL-запити, які виконуються реляційної СКБД.
Конкретні OLAP-продукти, як правило, являють собою або засіб багатовимірного подання даних, OLAP-клієнт (наприклад, Pivot Tables в Excel 2000 фірми Microsoft або ProClarity фірми Knosys), або багатовимірну серверну СКБД, OLAP-сервер (наприклад, Oracle Express Server або Microsoft OLAP Services).
Шар багатовимірної обробки зазвичай буває вбудований в OLAP-клієнт і/або в OLAP-сервер, але може бути виділений в чистому вигляді, як, наприклад, компонент Pivot Table Service фірми Microsoft.
Реалізація серверів
Як вже говорилося вище, засоби OLAP-аналізу можуть витягувати дані і безпосередньо з реляційних систем. Такий підхід був більш привабливим в ті часи, коли OLAP-сервери були відсутні в прайс-аркушах провідних виробників СКБД. Але сьогодні і Oracle, і Informix, і Microsoft пропонують повноцінні OLAP-сервери, і навіть ті IT-менеджери, які не люблять розводити у своїх мережах суміш з ПЗ різних виробників, можуть купити (точніше, звернутися з відповідним проханням до керівництва компанії) OLAP -сервер тієї ж марки, що і основний сервер баз даних.
OLAP-сервери, або сервери багатовимірних БД, можуть зберігати свої багатовимірні дані по-різному. Перш ніж розглянути ці способи, нам потрібно поговорити про такий важливий аспект, як зберігання агрегатів. Справа в тому, що в будь-якому сховищі даних - і в звичайному, і в багатовимірному - поряд з детальними даними, які видобуваються з оперативних систем, зберігаються і сумарні показники (агреговані показники, агрегати), такі, як суми обсягів продажів по місяцях, за категоріями товарів тощо. Агрегати зберігаються в явному вигляді з єдиною метою - прискорити виконання запитів. Адже, з одного боку, в сховищі накопичується, як правило, дуже великий об'єм даних, а з іншого - аналітиків в більшості випадків цікавлять не детальні, а узагальнені показники. І якщо кожен раз для обчислення суми продажів за рік довелося б підсумувати мільйони індивідуальних продажів, швидкість, скоріш за все, була б неприйнятною. Тому при завантаженні даних в багатовимірну БД обчислюються і зберігаються всі сумарні показники або їх частини.
Але за все треба платити. І за швидкість обробки запитів до сумарних даних доводиться платити збільшенням обсягів даних і часу на їх завантаження. Причому збільшення обсягу може стати буквально катастрофічним - в одному з опублікованих стандартних тестів повний підрахунок агрегатів для 10 Мб вихідних даних зажадав 2,4 ГБ, тобто дані виросли в 240 разів! Ступінь «розбухання» даних при обчисленні агрегатів залежить від кількості вимірювань куба і структури цих вимірів, тобто співвідношення кількості «батьків» і «дітей» на різних рівнях вимірювання. Для вирішення проблеми зберігання агрегатів застосовуються часом складні схеми, що дозволяють при обчисленні далеко не всіх можливих агрегатів досягати значного підвищення продуктивності виконання запитів.
Багатовимірне зберігання дозволяє звертатися до даних як до багатовимірного масиву, завдяки чому забезпечуються однаково швидкі обчислення сумарних показників і різні багатовимірні перетворення по кожному з вимірів. Деякий час тому OLAP-продукти підтримували або реляційне, або багатовимірне зберігання. Сьогодні, як правило, один і той самий продукт забезпечує ці обидва види зберігання, а також третій вид - змішаний.
Кожен з цих способів має свої переваги і недоліки і повинен застосовуватися в залежності від умов - обсягу даних, потужності реляційної СКБД тощо.
При зберіганні даних у багатовимірних структурах виникає потенційна проблема «розбухання» за рахунок зберігання порожніх значень. Адже якщо в багатовимірному масиві зарезервовано місце під всі можливі комбінації міток вимірювань, а реально заповнена лише мала частина (наприклад, ряд продуктів продається тільки в невеликому числі регіонів), тоді більша частина куба буде порожньою, хоча місце буде зайняте. Сучасні OLAP-продукти дозволяють справлятися з цією проблемою.
Компанія IBM
Рішення компанії IBM називається A Data Warehouse Plus. Метою компанії є забезпечення інтегрованого набору програмних продуктів і сервісів, заснованих на єдиній архітектурі. Основою сховищ даних є сімейство СКБД DB2. Перевагою IBM є те, що дані, які потрібно витягнути з оперативної бази даних і помістити в сховище даних, знаходяться в системах IBM. Тому природна тісна інтеграція програмних продуктів.
Пропонуються три рішення для сховищ даних:
- ізольована вітрина даних - призначена для вирішення окремих завдань поза зв'язком із загальним сховищем корпорації;
- залежна вітрина даних - аналогічна ізольованій вітрині даних, але джерела даних знаходяться під централізованим контролем;
- глобальне сховище даних - корпоративне сховище даних, яке повністю централізовано контролюється і керується. Глобальне сховище даних може зберігатися централізовано або складатися з декількох розподілених в мережі ринків даних.
Oracle
Рішення компанії Oracle в області сховищ даних ґрунтується на двох чинниках: широкий асортимент продуктів самої компанії і діяльність партнерів в рамках програми Warehouse Technology Initiative. Можливості Oracle в області сховищ даних базуються на таких складових:
- наявність реляційної СКБД Oracle 11, яка постійно вдосконалюється для кращого задоволення потреб сховищ даних;
- існування набору готових додатків, які забезпечують можливості розробки сховища даних;
- високий технологічний потенціал компанії в галузі аналізу даних;
- доступність низки продуктів, вироблених іншими компаніями.
Hewlett Packard
Роботи, пов'язані з OLAP, виконуються в рамках програми OpenWarehouse. Виконання цієї програми повинно забезпечити можливість побудови сховищ даних на основі потужних комп'ютерів HP, апаратури інших виробників і програмних компонентів. Основою підходу HP є Unix-платформи і програмний продукт Intelligent Warehouse, який призначений для керування сховищами даних. Основа побудови сховищ даних, пропонована HP, залишає свободу вибору реляційної СКБД, засобів реінжинірингу тощо.
NCR
Рішення компанії спрямоване на вирішення проблем корпорацій, у яких однаково сильні потреби і в системах підтримки прийняття рішень, і в системах оперативної аналітичної обробки даних. Пропонована архітектура називається Enterprise Information Factory і ґрунтується на досвіді використання системи керування базами даних Teradata і пов'язаних з нею методах паралельної обробки.
Informix Software
Стратегія компанії по відношенню до сховищ даних спрямована на розширення ринку для її продукту On-Line Dinamic Parallel Server. Запропонована архітектура сховища даних базується на чотирьох технологіях: реляційній бази даних, програмному забезпеченні для керування сховищем даних, засобах доступу до даних і платформі відкритих систем. Три останні компонента розробляються партнерами компанії. Після виходу Універсального Сервера, заснованого на об'єктно-реляційному підході, можна очікувати, що і він буде використовуватися для побудови OLAP.
SAS Institute
Компанія вважає себе постачальником повного рішення для організації сховища даних. Підхід заснований на наступному:
- забезпечення доступу до даних з можливістю їх витягання з найрізноманітніших сховищ даних (реляційних і нереляційних);
- перетворення даних і маніпулювання ними з використанням 4GL;
- наявність сервера багатовимірних баз даних;
- великий набір методів і засобів для аналітичної обробки та статистичного аналізу.
Sybase
Стратегія компанії в області сховищ даних ґрунтується на розробленій їй архітектурі Warehouse WORKS. В основі підходу перебуває реляційна СКБД Sybase Adaptive Server Enterprise 15.5, засіб для підключення та доступу до баз даних OmniCONNECT і засіб розробки додатків PowerBuilder. Компанія продовжує удосконалювати свою СКБД для кращого задоволення потреб сховищ даних (наприклад, введено побітну індексацію).
Software AG
Діяльність компанії в області сховищ даних відбувається в рамках програми Open Data Warehouse Initiative. Програма базується на основних продуктах компанії ADABAS і Natural 4GL, власних і придбаних засобах вилучення та аналізу даних, засобі керування сховищем даних SourcePoint, який дозволяє автоматизувати процес вилучення і пересилання даних, а також їх завантаження в сховище даних.
5. Відеоматеріали
Що таке Зведені таблиці Excel і OLAP куби
Шрифти
Розмір шрифта
Колір тексту
Колір тла
Кернінг шрифтів
Видимість картинок
Інтервал між літерами
Висота рядка
Виділити посилання
Вирівнювання тексту
Ширина абзацу