Хмарні технології в структурі ІОТ
5. Топологія та сховище об'єктів
5.3. Потік даних і обробка потоків
Оскільки дані потрапляють в інтерфейс IoT, важливо зрозуміти, як може змінюватися потік обробки даних. Залежно від сценаріїв та застосувань, записи даних можуть проходити через різні етапи, об'єднані в іншому порядку, і часто обробляються паралельними паралельними завданнями. Ці етапи можна класифікувати за чотирма категоріями: зберігання, маршрутизація, аналіз і дія/відображення:
• Зберігання включає в себе кеші пам'яті, тимчасові черги та постійні архіви.
• Маршрутизація дозволяє відправляти записи даних до однієї або більше кінцевих точок зберігання, процесів аналізу та дій.
• Аналіз використовується для запуску записів вхідних даних через набір умов і може виробляти різні вихідні дані записів. Наприклад, вхідна телеметрія, закодована в Avro, може повернути вихідну телеметрію, закодовану у форматі JSON.
• Записи оригінальних вхідних даних і записи вихідного аналізу зазвичай зберігаються і доступні для відображення, а також можуть ініціювати такі дії, як електронні листи, миттєві повідомлення, квитки на випадок, завдання CRM, команди пристроїв тощо
Ці процеси можуть бути
об'єднані в прості графіки, наприклад, для відображення необробленої
телеметрії, отриманої в реальному часі, або більше складні графіки, які
виконують кілька розширених завдань, наприклад, оновлення інформаційних
панелей, ініціювання тривог, і почати бізнес-інтеграційні процеси і т.д.
Наприклад, наступний графік являє собою простий сценарій, в якому
пристрої відправляють записи телеметрії, які тимчасово зберігається в
концентраторі Azure IoT, а потім негайно відображається на графіку на
екрані для візуалізації:

Наступний графік представляє інший поширений сценарій, в якому
пристрої відправляють телеметрію, зберігають її в короткостроковій
перспективі в Azure IoT Hub, незабаром після аналізу даних для виявлення
аномалій, викликають такі дії, як електронна пошта, текст SMS, миттєве
повідомлення повідомлення тощо:

Архітектура IoT може також складатися з декількох точок прийому.
Наприклад, деяке зберігання та / або аналіз телеметрії може відбуваються на
місці, в межах пристроїв і польових / крайових шлюзів; для підключення
можуть знадобитися переклади протоколів обмежених пристроїв до хмари.
Хоча отриманий графік є більш складним, логічні будівельні блоки є
однаковими:
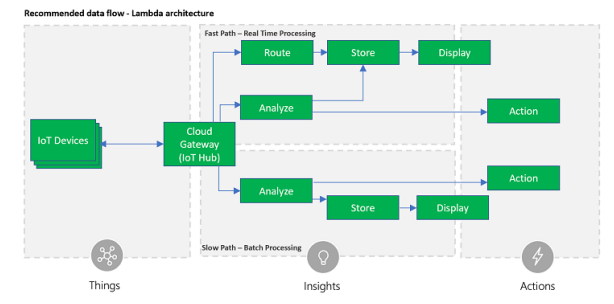
Рекомендований потік даних Ця довідкова архітектура припускає, що бізнес запускає кілька паралельних потокових процесорів, або шляхом секціонування вхідний потік, або шляхом пересилання записів даних до декількох конвеєрів. Рекомендується розділити на основі властивості повідомлень (наприклад, ідентифікатор пристрою, розташування пристрою, формат корисного навантаження тощо), щоб уникнути де-серіалізації корисного навантаження перед маршрутизацією але документ містить рішення, здатні здійснювати маршрутизацію на основі вмісту повідомлень JSON. Наступний графік, також відомий як Lambda архітектура, показує рекомендований потік повідомлень від пристрою до хмари і події в рішенні IoT. Записи даних проходять через два різних шляхи:
1. Швидкий процес архівування та відображення вхідних повідомлень, а також аналіз цих записів термін критичної інформації і дій, таких як тривоги.
2. Повільний конвеєр обробки, що виконує складний аналіз, наприклад,
поєднуючи дані з декількох джерел і протягом більш тривалого періоду часу
(наприклад, годин або днів) і створення нової інформації, наприклад, звітів,
машин моделей навчання тощо.
Варіанти технологій Існує декілька служб Azure та сторонніх розробників, які можна використовувати та комбінувати для створення надійного та масштабованого IoT архітектури, однак, при виборі служби для розгортання, деякі аспекти слід розглядати першими:
• Безстатистичний vs stateful: де це можливо, рішення повинно реалізувати процесори без стаціонару, щоб зменшити експлуатацію вартості та збільшення доступності. З іншого боку, обробка даних, що здійснюється за допомогою штату, дозволяє проводити більш різноманітний аналіз і часто є для реалізації функцій більш високого рівня.
• Статичні проти динамічних правил: якщо правила аналізу не змінюються і не посилаються на зовнішні дані, які змінюються, то це можна вибрати більш прості технології за нижчою ціною. У сценаріях, де потрібно більше гнучкості підтримують змінні навантаження, часті зміни в логіці обробки потоків і змінні зовнішні довідкові дані доступні технології є більш складними і дорогими для розгортання.
Документ представляє два варіанти, один для розв'язання простих сценаріїв з процесорами без статусу та досить статичними правилами, і один складний сценарій, наприклад, процесори, що підтримують стан, з логікою динамічного аналізу та довідковими даними. Наступні рішення представлені з припущенням, що керовані Azure послуги збільшують загальну систему безпеки та зниження витрат на установку та обслуговування. З іншого боку, розробники можуть створювати рішення гетерогенні системи, що поєднують керовані послуги з власними, сторонніми або відкритими компонентами, такими як Spark та Cassandra, використовуючи інші пропозиції Azure, такі як віртуальні машини Azure, послуги контейнерів Azure, та Azure HDInsight.
Обробка потоку без статусу
Наступна архітектура надає рішення для швидкого та масштабованого
аналізу записів даних в реальному часі, в сценарії, де необхідний лише аналіз
без участі громадян, використовуючи невеликий набір простих логічних
правил. Також включено повільний шлях, дозволяє виконувати більш
складний аналіз, наприклад, завдання на машинне навчання, без обмежень
швидкості швидкий шлях
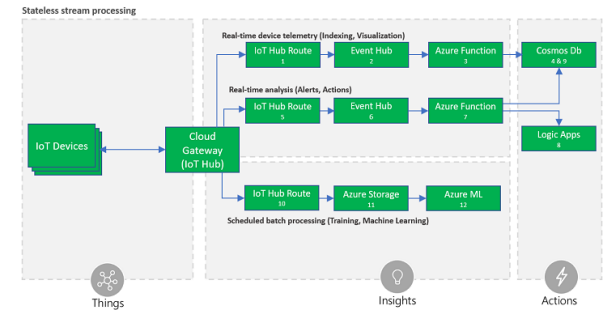
Ця архітектура рекомендується для сценаріїв, де записи вхідних даних
серіалізуються в JSON, і правила обробки беруть вхідне повідомлення за
один раз, не враховуючи історичних даних. Архітектура використовує
можливість визначення умов на корисному навантаженні (# 5) в Azure IoT
Hub, щоб переслати лише певні повідомлення та дії тригера в послуги,
підключені через логічні програми
Переваги архітектури: 1. Висока доступність завдяки географічній надмірності та швидким можливостям відновлення після аварії служб Azure. 2. Низька вартість: більшість компонентів автоматично масштабуються, пристосовуючись до змінної навантаження, мінімізуючи витрати коли немає даних для обробки. 3. Мінімальні експлуатаційні витрати, оскільки всі компоненти керуються службами Azure. 4. Гнучкість: функції Azure і Azure Cosmos DB дозволяють трансформувати дані в будь-яку бажану схему, підтримка декількох шаблонів доступу та API, таких як API MongoDB, Cassandra і Graph. 5. Дії та бізнес-інтеграція: широкий вибір інтеграцій доступний через програми Logic Apps та Azure ML.
Коли використовувати цю архітектуру:
1. Записи вхідних даних серіалізуються у форматі JSON.
2. Необхідно невелика кількість правил. В даний час концентратор Azure
IoT підтримує до 100 маршрутів.
3. Записи даних можна аналізувати по черзі; тобто немає необхідності
агрегувати дані по безлічі точок даних
(наприклад, усереднення) або потоки даних (наприклад, об'єднання
даних з декількох пристроїв).
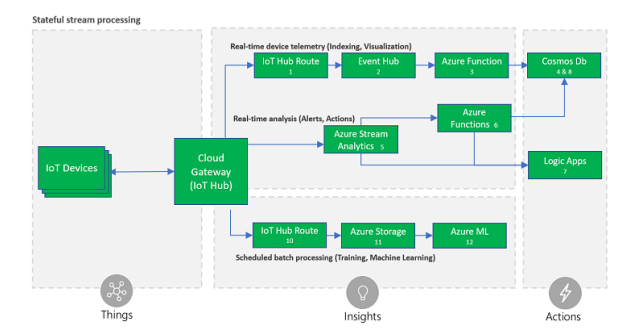
Архітектура схожа з рішенням, рекомендованим для обробки без
тривалості, тільки шлях заміни аналізу
Аналітика Azure Stream (ASA) (# 5).
ASA призначений для гіпер-масштабного аналізу і маршрутизації
записів даних, що є в стані, з можливістю застосування
складні запити протягом періодів часу і декількох потоків. Запити
визначаються за допомогою SQL-схожої мови, що дозволяє
перетворення і обчислення. Служба підтримує запізнілі (до 21 дня) та
позачергові (до однієї години) події,
при обробці за часом застосування35
Таким чином, висновок затримується на різницю в часі.
ASA також гарантує точно після доставки на підтримувані пункти
призначення, з невеликою кількістю документів36
винятки, які можуть
генерувати дублікати. Мова запитів дозволяє оптимізувати аналіз
продуктивності за допомогою розпаралелювання і розриву
запити.
ASA також підтримує записи даних у форматі Avro - компактний
двійковий формат, який використовується для зменшення затримки та витрат
на пропускну здатність.
Окрім обробки потоку ASA, в цій архітектурі використовується один
маршрут маршрутизації Azure IoT Hub
телеметрії (# 1) до функції Azure (# 3), яка може перетворити її в інший
формат, наприклад, приєднання до зовнішньої інформації,
і зберігати його в Cosmos DB (# 4) для споживання, наприклад,
відображення на інформаційній панелі.
Окремий маршрут концентратора Azure IoT (# 10) використовується для
копіювання всіх вхідних записів даних до блоків зберігання Azure (# 11), де
можуть бути архівовані на невизначений термін за низькою ціною і
легко доступні для пакетної обробки, такі як Azure Machine Learning
завдання з наукової інформації (№ 12).
Переваги архітектури:
1. Висока доступність завдяки географічній надмірності та швидкому відновленню аварійних функцій служб Azure. 2. Мінімальні експлуатаційні витрати, оскільки всі компоненти керуються службами Azure. 3. Здатність Azure Stream Analytics виконувати комплексний аналіз в масштабі, наприклад, використання обкатки / ковзання / стрибків вікна, агрегації потоків і зовнішні джерела даних. 4. Гнучкість: функції Azure і Cosmos DB дозволяють трансформувати дані в будь-яку бажану схему, підтримка декількох шаблонів доступу та API, таких як API MongoDB, Cassandra і Graph. 5. Дії та бізнес-інтеграція: широкий вибір інтеграцій доступний через програми Logic Apps та Azure ML. 6. Продуктивність: підтримка двійкових потоків даних, щоб зменшити затримку.
Коли для реалізації цієї архітектури:
1. Записи вхідних даних вимагають складного аналізу, такого як часові
вікна, агрегація потоків або об'єднання з зовнішніми
джерел даних, що неможливо з архітектурою без громадянства.
2. Логіка обробки складається з декількох правил або логічних одиниць,
які можуть зростати з часом.
3. Вхідна телеметрія ріалізується у двійковому форматі, як Avro
Шрифти
Розмір шрифта
Колір тексту
Колір тла
Кернінг шрифтів
Видимість картинок
Інтервал між літерами
Висота рядка
Виділити посилання
Вирівнювання тексту
Ширина абзацу